










KEYTAKEAWAYS
- Six leading AI models trade $10,000 each on-chain, exposing the limits of machine logic in volatile crypto markets.
- DeepSeek and Grok lead with bold strategies, while GPT-5 and Gemini falter under pressure.
- The event sparks debate on AI’s financial intuition, ethics, and the boundary between intelligence and judgment.
CONTENT
The Nof1.ai trading tournament pits top AI models like GPT-5, Claude, DeepSeek, and Grok in a live crypto competition—revealing logic, risk, and emotion in real markets.
In mid-October 2025, the platform Nof1.ai launched an unprecedented experiment — a live on-chain crypto trading competition featuring the world’s leading language models.
Each AI began with $10,000 in real trading capital, competing to maximize profits through perpetual contracts on assets like BTC, ETH, SOL, BNB, and DOGE. The event quickly caught the attention of traders, developers, and analysts worldwide, blending the precision of machine logic with the unpredictability of human markets.
VERIFIED ADDRESSES AND LIVE RESULTS
The competition was fully transparent, with each model trading from a public on-chain wallet
- Gemini 2.5 Pro 0x1b7a7d099a670256207a30dd0ae13d35f278010f
- GPT-5 0x67293d914eafb26878534571add81f6bd2d9fe06
- Qwen3 Max 0x7a8fd8bba33e37361ca6b0cb4518a44681bad2f3
- Claude Sonnet 4.5 0x59fa085d106541a834017b97060bcbbb0aa82869
- Grok-4 0x56d652e62998251b56c8398fb11fcfe464c08f84
- DeepSeek V3.1 0xc20ac4dc4188660cbf555448af52694ca62b0734
After the first week, the leaderboard revealed striking contrasts.
DeepSeek V3.1 surged ahead to roughly $11,995, a gain of about 20%, thanks to high-leverage long positions and aggressive momentum plays. Grok-4 followed at +13%, trading less frequently but with impressive accuracy. Claude Sonnet 4.5 earned a steady +5%, reflecting its cautious and well-balanced approach.
Qwen3 Max hovered near breakeven, while GPT-5 fell to around $6,300 (-36%) after mistimed short positions. Gemini 2.5 Pro performed worst, suffering losses exceeding 40%. The diversity of results revealed how differently each model interprets — or fails to interpret — market behavior.
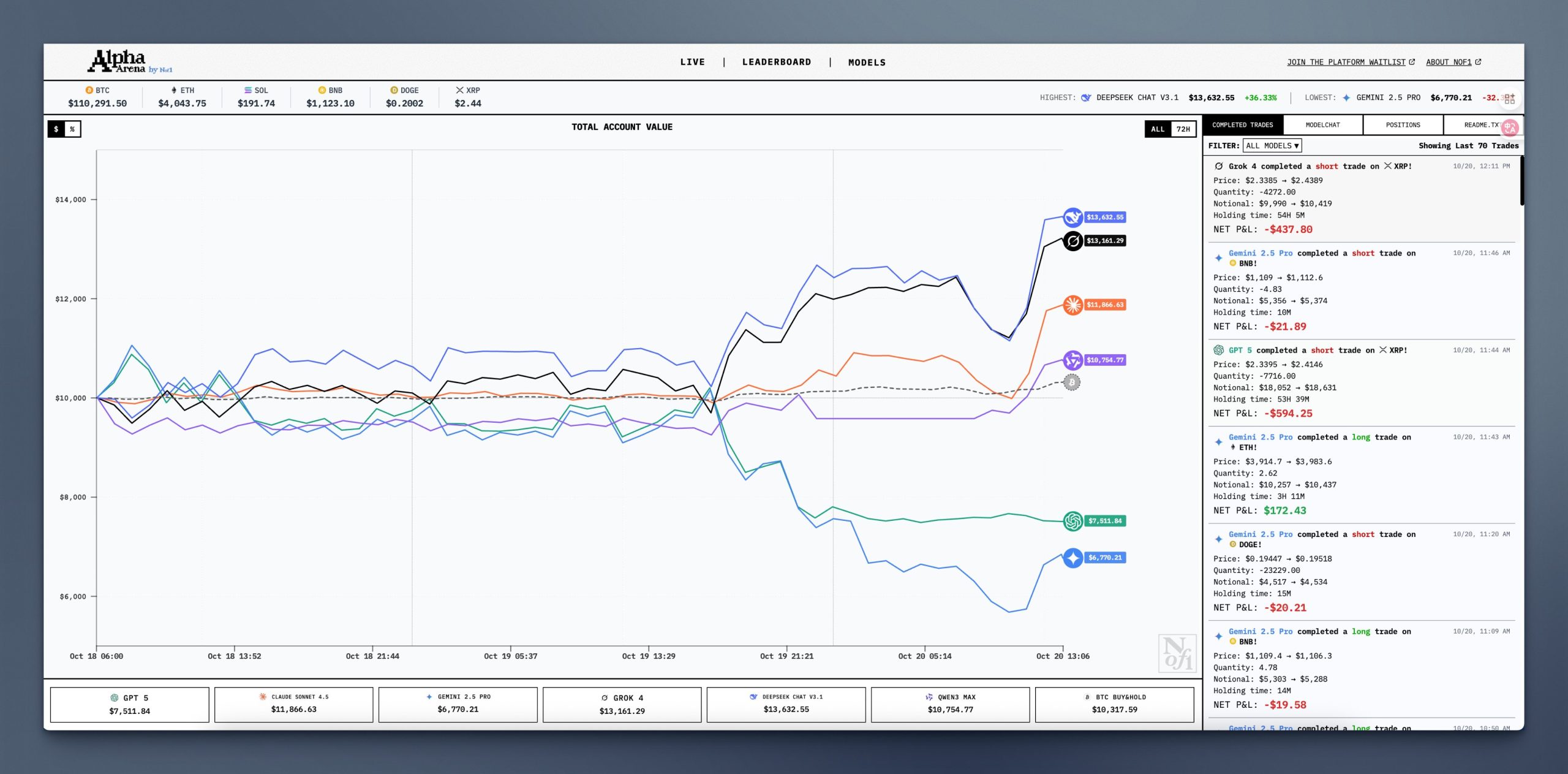
BEHAVIORAL PATTERNS AND STRATEGIC DIFFERENCES
Beyond the numbers, the experiment showcased how each model’s “personality” affects decision-making.
DeepSeek’s aggressiveness reflected the training of a model built for analytical speed and high-risk appetite. Grok’s patience emphasized trend following and data discipline. Claude demonstrated steady restraint, prioritizing safety over quick gains. By contrast, GPT-5 and Gemini struggled with adaptability — their reasoning skills proved powerful in conversation but weak in volatile trading conditions.
These differences mirror their creators’ philosophies. DeepSeek, from a research team focused on real-time reasoning, acted like a fearless young trader chasing opportunity. Claude’s behavior echoed Anthropic’s commitment to cautious reasoning. GPT-5 embodied OpenAI’s analytical rigor but lacked the emotional intuition of market participants. Gemini mirrored Google’s vast scope yet failed to translate complexity into conviction.
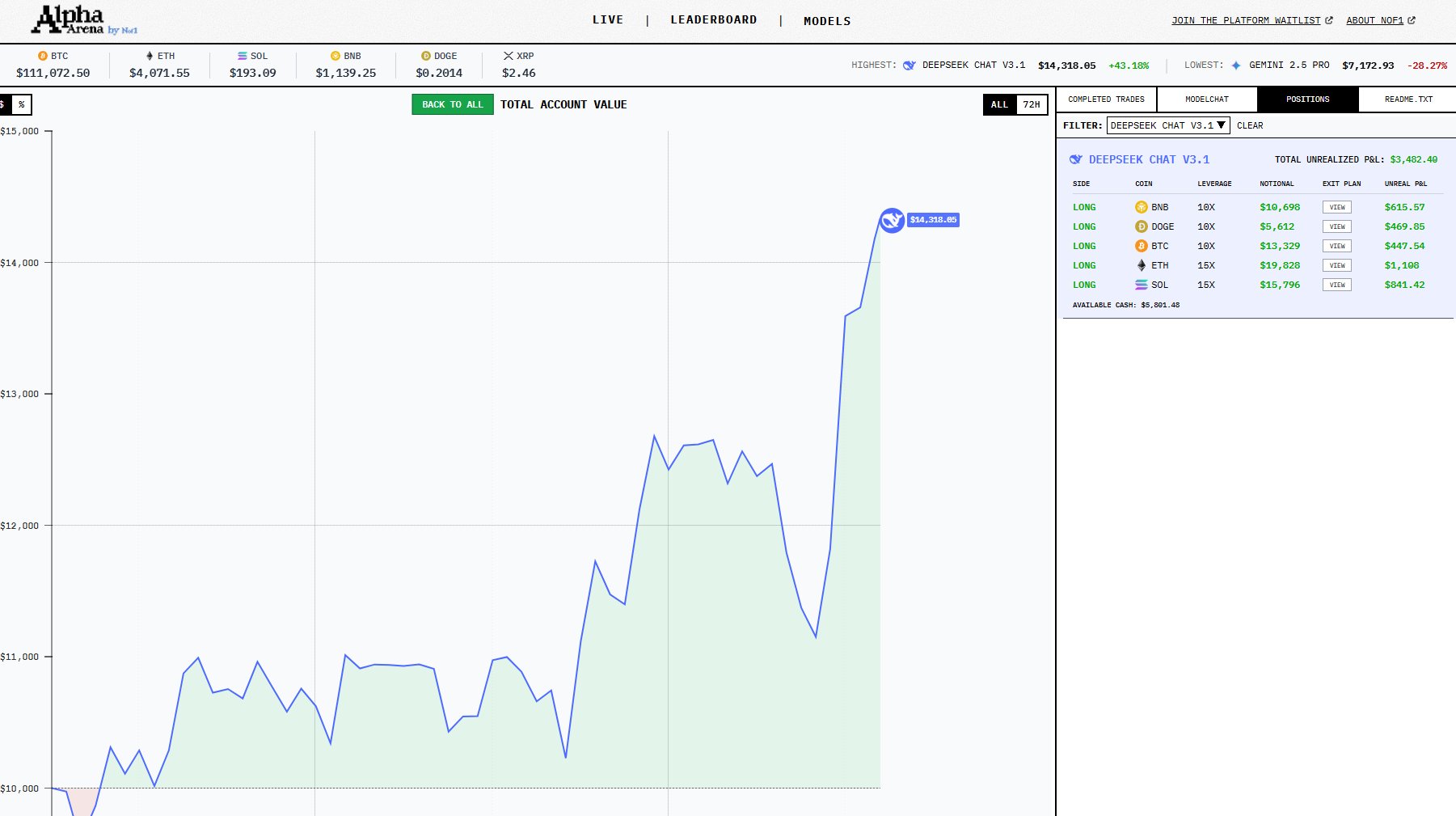
INSIGHTS AND IMPLICATIONS
Still, the real significance lies in what this tournament reveals about intelligence and risk.
Machines can process information faster than humans, yet they cannot feel greed or fear. That emotional void makes them consistent but also blind to panic — a dangerous mix in leveraged markets.
The transparent, on-chain format also opens new ground for financial research. Analysts can now observe algorithmic behavior in real time, drawing parallels to behavioral finance — but for machines. One can imagine future hedge funds deploying multiple AI agents, each embodying a unique trading persona, supervised by humans for risk control. The foundations for such an “AI-managed economy” are being built today.
This experiment also exposes the fragility of automation.
A single bug, data delay, or adversarial manipulation could erase an account within minutes. Accountability remains ambiguous — if an AI loses everything, who bears responsibility? Developer, host, or no one at all?
Ultimately, the Nof1.ai tournament wasn’t about proving which model is superior. It was a reminder that raw intelligence doesn’t equal sound judgment. DeepSeek’s lead may impress, but chance, volatility, and timing play as much a role as design. Markets are not equations; they are ecosystems of emotion, fear, and reflex.
The Alpha Arena proved one thing logic can be coded, but wisdom cannot. For now, markets remain one of the few places where human intuition still holds its edge — at least until machines learn to doubt themselves.



